Without filter With BPF filter
Network Userspace Network Userspace
┌───────┐ ┌─────────┐ ┌───────┐ ┌─────────┐
│ ARP │──→│ ARP │ │ ARP │──→│ ARP │
│ IPv4 │──→│ IPv4 │ │ IPv4 │ │ reply │
│ ARP │──→│ ARP │ │ ARP │ │ │
│ IPv6 │──→│ IPv6 │ │ IPv6 │ │ │
│ IPv4 │──→│ IPv4 │ │ IPv4 │ │ │
│ ARP │──→│ ARP │ │ ARP │ │ │
│ ... │──→│ ... │ │ ... │ │ │
└───────┘ └─────────┘ └───────┘ └─────────┘
~10,000 ~10,000 ~10,000 ~100
packets copied packets copied
App filters in userspace Kernel filters before copy
The problem: discovering VM IP addresses without a guest agent
In a recent change to qcontroller, I removed the dependency on QEMU Guest Agent (QGA) for discovering a VM’s IP address. Previously, users had to install QGA inside every VM—easy enough with cloud-init, but still a hard requirement just to answer the question “what IP did this VM get?”
The alternative: ARP scanning. I already control the MAC addresses assigned to VMs, so I can periodically broadcast ARP requests on the virtual network interface and match the replies against known MACs. Pure Layer 2, no guest cooperation needed.
This post isn’t about the ARP scanner itself (that’s in PR #26). It’s about a problem I hit on macOS, and how six lines of BPF bytecode solved it. The BPF filter is implemented in PR #27.
Raw sockets on macOS: there aren’t any
On Linux, you open an AF_PACKET socket, bind it to an interface, and you’re reading raw Ethernet frames. macOS doesn’t support AF_PACKET. Instead, you go through BPF—Berkeley Packet Filter.
The setup looks roughly like this:
- Open
/dev/bpf0 (or /dev/bpf1, /dev/bpf2, … — you try them until one is available)
- Bind it to a network interface with
BIOCSETIF
- Enable immediate mode with
BIOCIMMEDIATE so reads return as soon as a packet arrives, rather than waiting for the buffer to fill
- Optionally enable promiscuous mode with
BIOCPROMISC
- Read from the file descriptor—you get raw Ethernet frames, each prefixed by a
bpf_hdr struct
This works. But there’s a catch.
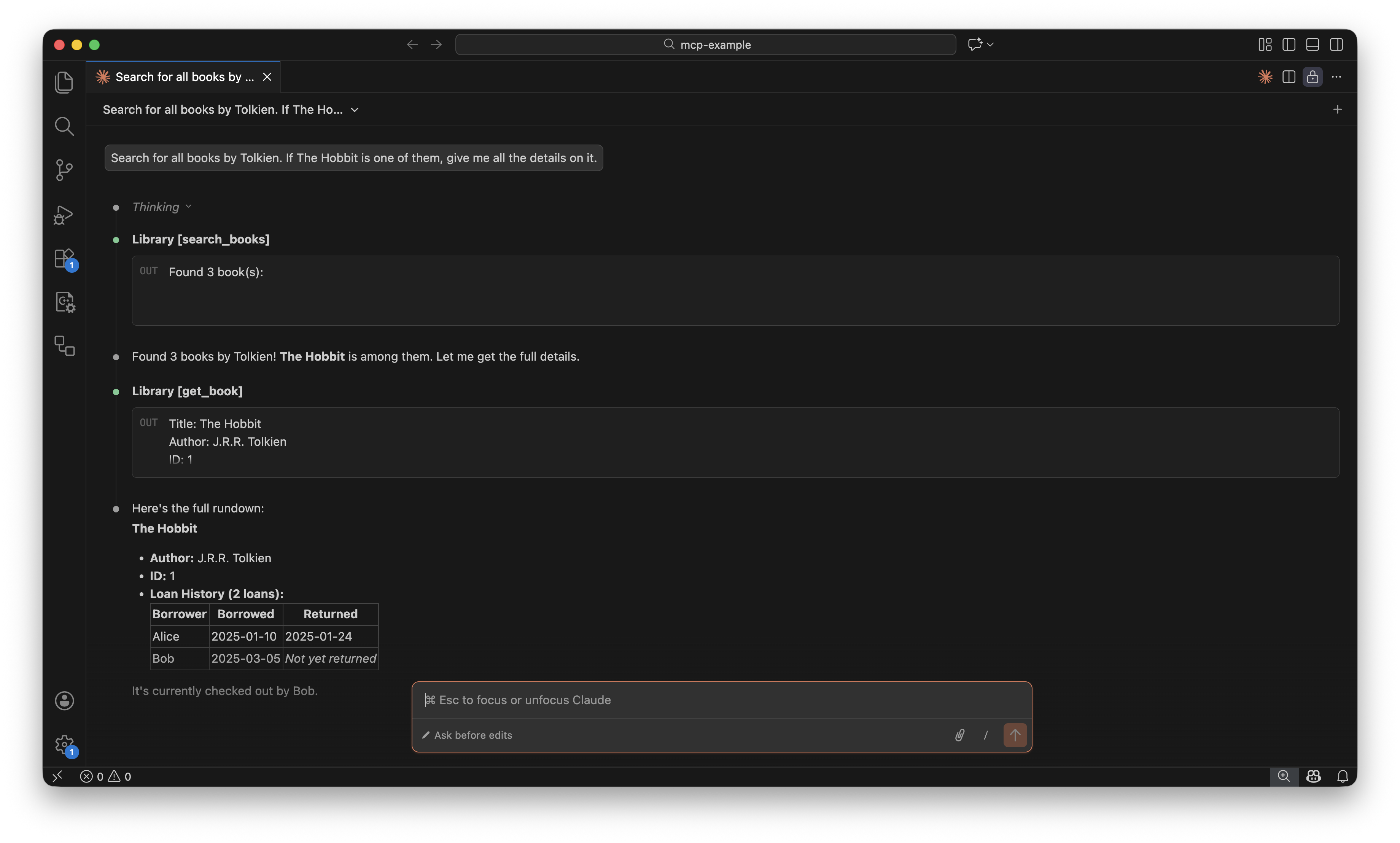
The flood
Promiscuous mode means the BPF device captures everything on the wire—not just frames addressed to your MAC. On my home network, which has maybe a dozen devices, a few seconds of capture produced roughly:
- ~9,400 ARP frames (requests and replies from all devices)
- ~190 IPv4 frames
- ~50 IPv6 frames
That’s about 10,000 frames copied from kernel to userspace, where my Go code then checks each one: is it ARP? Is it a reply? Does the sender MAC match a VM I care about? For 99% of those frames, the answer is no.
On a busier network—an office, a data center—this gets much worse. We’re doing an O(n) scan of the entire network’s chatter to find the handful of ARP replies we actually need. The kernel already has all these frames in its buffers; we’re just making it copy them all to us so we can throw most away.
BPF is more than a packet source
Here’s the coolest thing about BPF: it’s not just a mechanism for reading packets. It includes a programmable filter that runs inside the kernel, before packets are copied to userspace. The “F” in BPF stands for Filter, and that filter is the interesting part.
BPF defines a small virtual machine with:
- Two registers:
A (accumulator) and X (index), both 32-bit
- A small instruction set: load, store, jump, arithmetic, return
The VM operates on the raw packet data. Instructions can load bytes from specific offsets in the packet, compare them, and either accept or reject the packet. The kernel runs this program on every incoming frame. Only frames that pass the filter get copied to userspace.
This is the same mechanism that powers tcpdump expressions. When you write tcpdump arp, tcpdump compiles that into BPF bytecode and installs it via BIOCSETF. We can do the same thing.
The Ethernet frame layout
To write a BPF filter, you need to know exactly what bytes you’re looking at. An Ethernet frame carrying an ARP message is 42 bytes:
Ethernet header (14 bytes):
[0:6] Destination MAC (broadcast: ff:ff:ff:ff:ff:ff)
[6:12] Source MAC
[12:14] EtherType ← 0x0806 means ARP
ARP payload (28 bytes):
[14:16] Hardware type (1 = Ethernet)
[16:18] Protocol type (0x0800 = IPv4)
[18] Hardware addr len (6)
[19] Protocol addr len (4)
[20:22] Operation ← 1 = request, 2 = reply
[22:28] Sender MAC
[28:32] Sender IP
[32:38] Target MAC
[38:42] Target IP
Two fields matter for filtering:
- Byte offset 12 (2 bytes): the EtherType. If it’s not
0x0806, this isn’t ARP—drop it.
- Byte offset 20 (2 bytes): the ARP opcode. If it’s not
0x0002, this isn’t a reply—drop it.
The filter: six instructions
Here’s the complete BPF program using the BPF_STMT/BPF_JUMP macros from the bpf(4) man page:
BPF_STMT(BPF_LD+BPF_H+BPF_ABS, 12), // A = halfword at offset 12 (EtherType)
BPF_JUMP(BPF_JMP+BPF_JEQ+BPF_K, 0x0806, 0, 3), // if A == 0x0806 (ARP) continue, else skip 3 to drop
BPF_STMT(BPF_LD+BPF_H+BPF_ABS, 20), // A = halfword at offset 20 (ARP opcode)
BPF_JUMP(BPF_JMP+BPF_JEQ+BPF_K, 0x0002, 0, 1), // if A == 0x0002 (reply) continue, else skip 1 to drop
BPF_STMT(BPF_RET+BPF_K, 0xFFFFFFFF), // ACCEPT: return entire packet
BPF_STMT(BPF_RET+BPF_K, 0), // DROP: return 0 bytes (discard)
BPF_STMT(code, k) encodes a non-branching instruction. BPF_JUMP(code, k, jt, jf) encodes a conditional branch where jt and jf are the number of instructions to skip forward on true/false. The code field is built by combining a class (BPF_LD, BPF_JMP, BPF_RET), a size (BPF_H for halfword—2 bytes), and an addressing mode (BPF_ABS for absolute packet offset, BPF_K for constant).
A BPF_RET instruction tells the kernel how many bytes of the packet to copy to userspace. Returning 0xFFFFFFFF (the maximum uint32) means “copy the entire packet.” Returning 0 means “copy nothing”—i.e., drop the packet.
BPF_JUMP takes two skip counts: jt (jump true) and jf (jump false). A skip of 0 means “don’t skip, just execute the next instruction”—sometimes called falling through. A skip of 3 means “skip the next 3 instructions.”
Let’s trace through what happens for different packets:
An ARP reply arrives. BPF_LD loads bytes [12:14] into A: 0x0806. BPF_JEQ compares against 0x0806: match, jt=0, so we fall through. Next BPF_LD loads bytes [20:22]: 0x0002. BPF_JEQ compares against 0x0002: match, fall through. BPF_RET returns 0xFFFFFFFF—the kernel copies the full packet to userspace.
An ARP request arrives. Same path through the first three instructions, but bytes [20:22] contain 0x0001 (request, not reply). BPF_JEQ: no match, jf=1, skip 1 instruction forward—past the accept—landing on BPF_RET returning 0. Packet dropped. Never reaches userspace.
An IPv4 packet arrives. BPF_LD loads bytes [12:14]: 0x0800. BPF_JEQ against 0x0806: no match, jf=3, skip 3 instructions forward, landing directly on the drop. Two instructions and it’s done. The kernel never even looks at the ARP opcode field.
Most traffic on a network is IPv4/IPv6, and it gets rejected after just two instructions—a load and a conditional jump. The kernel doesn’t copy a single byte to userspace for those packets.
Writing it in Go
Go’s syscall package has BpfStmt and BpfJump functions for constructing BPF instructions, but they’re deprecated. The recommended replacement is golang.org/x/net/bpf, which provides typed instruction structs:
var arpReplyFilter = []bpf.Instruction{
bpf.LoadAbsolute{Off: 12, Size: 2}, // BPF_LD+BPF_H+BPF_ABS k=12
bpf.JumpIf{Cond: bpf.JumpEqual, Val: 0x0806, SkipFalse: 3}, // BPF_JMP+BPF_JEQ+BPF_K k=0x0806 jt=0 jf=3
bpf.LoadAbsolute{Off: 20, Size: 2}, // BPF_LD+BPF_H+BPF_ABS k=20
bpf.JumpIf{Cond: bpf.JumpEqual, Val: 0x0002, SkipFalse: 1}, // BPF_JMP+BPF_JEQ+BPF_K k=0x0002 jt=0 jf=1
bpf.RetConstant{Val: 0xFFFFFFFF}, // BPF_RET+BPF_K k=0xFFFFFFFF
bpf.RetConstant{Val: 0}, // BPF_RET+BPF_K k=0
}
Each Go struct maps directly to a BPF instruction. LoadAbsolute{Off: 12, Size: 2} is BPF_STMT(BPF_LD+BPF_H+BPF_ABS, 12)—load a halfword (2 bytes) from absolute packet offset 12. JumpIf{Cond: bpf.JumpEqual, Val: 0x0806, SkipFalse: 3} is BPF_JUMP(BPF_JMP+BPF_JEQ+BPF_K, 0x0806, 0, 3)—SkipFalse: 3 means “if not equal, skip 3 instructions forward” (landing on the final BPF_RET that drops the packet).
The bpf.Assemble function compiles these typed instructions into raw bytecode ([]bpf.RawInstruction). But here’s where it gets interesting: golang.org/x/net/bpf doesn’t provide a function to install the filter on a macOS BPF device. It does for Linux sockets (SO_ATTACH_FILTER), but the macOS BIOCSETF ioctl needs a syscall.BpfProgram struct pointing to syscall.BpfInsn values. Fortunately, bpf.RawInstruction and syscall.BpfInsn have identical memory layouts—both are {Op uint16, Jt uint8, Jf uint8, K uint32}—so an unsafe.Pointer cast works:
func setBPFFilterARPReply(fd int) error {
raw, err := bpf.Assemble(arpReplyFilter)
if err != nil {
return fmt.Errorf("failed to assemble BPF filter: %w", err)
}
prog := syscall.BpfProgram{
Len: uint32(len(raw)),
Insns: (*syscall.BpfInsn)(unsafe.Pointer(&raw[0])),
}
_, _, errno := syscall.Syscall(
syscall.SYS_IOCTL,
uintptr(fd),
syscall.BIOCSETF,
uintptr(unsafe.Pointer(&prog)),
)
if errno != 0 {
return fmt.Errorf("BIOCSETF failed: %v", errno)
}
return nil
}
Testing without hardware
One of the nice things about golang.org/x/net/bpf is that it includes bpf.NewVM, a userspace BPF interpreter. You can feed it your filter program and run arbitrary byte slices through it to verify the accept/drop logic without opening any devices or network interfaces:
func TestARPReplyFilter_DropsARPRequest(t *testing.T) {
vm, err := bpf.NewVM(arpReplyFilter)
require.NoError(t, err)
frame := buildARPRequest(
net.HardwareAddr{0x11, 0x22, 0x33, 0x44, 0x55, 0x66},
net.IP{10, 0, 0, 1},
net.IP{10, 0, 0, 2},
)
verdict, err := vm.Run(frame)
require.NoError(t, err)
assert.Zero(t, verdict, "ARP request should be dropped")
}
vm.Run returns the number of bytes the filter would accept. Zero means drop. This makes BPF filter logic fully unit-testable—no root privileges, no network interfaces, no platform dependencies.
The result
Before the filter, with debug logging enabled to count frames:
Received frame: 0x0806
Received frame: 0x0800
Received frame: 0x0806
Received frame: 0x86dd
Received frame: 0x0800
...
(~10,000 frames in a few seconds)
0x0806 is ARP, 0x0800 is IPv4, 0x86dd is IPv6—all mixed together, all copied to userspace.
After installing the filter:
Received frame: 0x0806
Received frame: 0x0806
Received frame: 0x0806
...
(~100 frames in a few seconds)
Only 0x0806. Only ARP replies. A ~100x reduction in packets reaching userspace, achieved by six instructions running in the kernel. The CPU and memory cost of processing those extra 9,900 frames per scan cycle is simply gone.
Beyond ARP: other things you can filter
The same pattern applies any time you want to isolate a specific type of traffic. A BPF filter is just a sequence of field checks at fixed byte offsets — once you know the layout of the packet you’re after, writing the filter is mechanical. A few examples:
HTTP/HTTPS traffic (custom sniffer for a specific service). Three layers: EtherType 0x0800 at offset 12, IP protocol 0x06 (TCP) at offset 23, TCP destination port at offset 36. Matching two ports requires two JumpIf instructions — the first jumps to accept on port 80, the second drops anything that isn’t 443:
var httpFilter = []bpf.Instruction{
bpf.LoadAbsolute{Off: 12, Size: 2},
bpf.JumpIf{Cond: bpf.JumpEqual, Val: 0x0800, SkipFalse: 6}, // IPv4?
bpf.LoadAbsolute{Off: 23, Size: 1},
bpf.JumpIf{Cond: bpf.JumpEqual, Val: 0x06, SkipFalse: 4}, // TCP?
bpf.LoadAbsolute{Off: 36, Size: 2}, // dst port
bpf.JumpIf{Cond: bpf.JumpEqual, Val: 80, SkipTrue: 1}, // port 80 → accept
bpf.JumpIf{Cond: bpf.JumpEqual, Val: 443, SkipFalse: 1}, // port 443 → accept
bpf.RetConstant{Val: 0xFFFFFFFF},
bpf.RetConstant{Val: 0},
}
This assumes a standard 20-byte IP header. It also only matches the destination port — outgoing requests. To catch responses too, add the same OR check against the source port at offset 34.
ICMP only (ping traffic, latency tooling). Check EtherType 0x0800 at offset 12, then load the IP protocol byte at offset 23 and compare to 0x01. Two checks — done.
DNS (queries and replies). EtherType 0x0800 at offset 12, IP protocol 0x11 (UDP) at offset 23, then the 2-byte UDP destination port at offset 36 equal to 0x0035 (53). Three checks; everything else is gone before it reaches your code.
DHCP (watching address assignments on a local network). Same shape as DNS — EtherType 0x0800, UDP — but match destination port 0x0043 (67, server) or 0x0044 (68, client).
Traffic from a specific MAC address. The source MAC sits at offsets 6–11 in the Ethernet header. Load 4 bytes at offset 6, compare to the upper 32 bits of the target MAC; load 2 bytes at offset 10, compare to the lower 16 bits. Two checks, no IP layer involved.
The principle is always the same: find the fixed-offset fields that uniquely identify the traffic you want, put the most common rejection first, and jump to the drop on mismatch. The kernel handles the rest.
Takeaway
If you’re doing any kind of raw packet capture on macOS through /dev/bpf*, installing a filter is straightforward and the performance difference is dramatic. Six instructions, two conditional checks, and the kernel does the work for you.
One constraint worth knowing: classic BPF on macOS is read-only. You can observe and filter packets, but you cannot modify or inject them. If that’s a requirement, you’ll need a different approach.
]]>